

Je mehr sich der Hype um NoSQL-Datenbanken legt, desto interessanter wird die Frage, wann sich der Einsatz einer solchen Datenbank wirklich lohnt. Werfen wir einen Blick auf die Dokumenten-Datenbanken wie MongoDB und CouchDB.
Was können Dokumentendatenbanken? (Und was nicht?)
Dokumentendatenbanken können, im Gegensatz zu relationalen Datenbanken, besonders gut hierarchische Daten speichern. Das heißt: Auch verschachtelt strukturierte Daten können einfach geladen und gespeichert werden. Somit entfallen aufwändige Tabellen-Konstruktionen, um die Daten zu speichern und komplexe Join-Operationen, um die Daten wieder zu laden. Wenn als Analogie eine relationale Datenbank einer Sammlung von CSV-Dokumenten entspricht, dann entspricht eine Dokumentendatenbank einer Sammlung von XML-Dokumenten.
Zusätzlich bieten Dokumentendatenbanken eine erstaunliche Flexibilität für die Datenstrukturen: Jedes Dokument darf unterschiedlich zusammengesetzt sein. Trotzdem kann man Dokumente effizient suchen, solange sie gemeinsame Strukturen enthalten. Anders als in einer relationalen Datenbank wird kein Schema explizit vorgegeben, sondern die gespeicherten Daten definieren implizit das verwendete Schema.
Diese schöne Welt hat aber auch ihre Schattenseiten, zumindest, wenn man aus der relationalen Welt kommt. Zum einen bieten MongoDB und CouchDB zwar atomare Zugriffe auf einzelne Entitäten, aber keine Transaktionen zum gemeinsamen Zugriff auf mehrere Entitäten. Zum anderen gibt es keine mit den relationalen Datenbanken vergleichbaren Join-Operationen, um Daten aus mehreren Entitäten gemeinsam zu durchsuchen bzw. zu laden.
Diese letzten beiden Punkte fallen schnell ins Gewicht, wenn eine Dokumentendatenbank zum ersten Mal eingesetzt wird. Darum sollte man sich klar sein, aus welchen Anforderungen heraus Dokumentendatenbanken entstanden sind: Das Ziel war, komplexe Daten schnell zu verarbeiten, auch bei großen Datenmengen mit sehr vielen Zugriffen. Die atomare Verarbeitung einzelner Entitäten ohne Unterstützung für Transaktionen liefert die Grundlage für eine massive Skalierbarkeit der Datenbank. Zusätzlich werden Daten häufig denormalisiert gespeichert, d.h. redundant in mehreren Dokumenten, damit eine Anwendung mit besonders wenigen Zugriffen auf den Datenspeicher auskommt.
Für welche Anwendungen eignet sich eine Dokumentendatenbank? (Und für welche nicht?)
Passende Einsatzgebiete einer MongoDB oder CouchDB sind Anwendungen mit reichhaltigen Domänenmodellen sowie Anwendungen, die sich sehr flexibel an unterschiedliche Anforderungen anpassen lassen müssen.
Anwendungen kommen zu einem reichhaltigen Domänenmodell, wenn man die Ideen des Domain-Driven Designs umsetzt. Der Grundgedanke ist dabei, den Programmcode fachlich zu strukturieren, sodass die Geschäftsdaten und die darauf basierende Logik eng miteinander gekoppelt sind.
Bei der Strukturierung einer Anwendung auf Basis des Domain-Driven Designs hilft es, sich an den so genannten Aggregates einer Anwendung zu orientieren. Ein Aggregate ist eine komplexe Datenstruktur aus mehreren Objekten, aber mit einem einzigen Einstiegspunkt, der von außen referenziert wird. Alle Objekte eines Aggregates haben einen gemeinsamen Lebenzyklus. Ein einfaches Beispiel ist eine Bestellung mit ihren Bestellpositionen: Ohne eine Bestellung gibt es keine Bestellpositionen und beim Löschen einer Bestellung werden auch die Bestellpositionen hinfällig.
Relational modelliert erstrecken sich solche Aggregates in der Regel über mehrere Datenbanktabellen mit 1:1- bzw. 1:n-Kardinalitäten. In einer Dokumentendatenbank lassen sich Aggregates bequem in einzelnen Dokumenten speichern, wie das folgende Bild schemahaft zeigt:
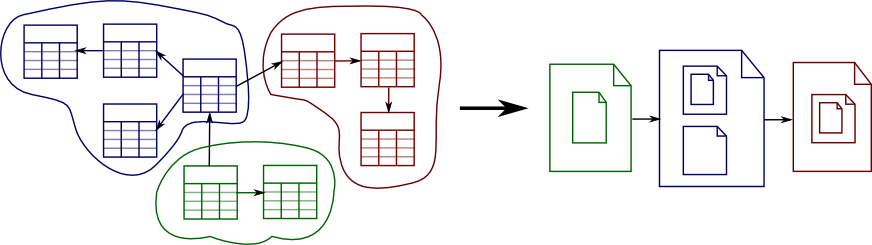
Andere Anwendungen müssen sehr flexibel darin sein, für unterschiedliche Anwender bzw. Anwendungsgebiete unterschiedliche Daten zu speichern und zu verarbeiten. Dazu gehören z.B. CRM-Produkte mit konfigurierbaren Feldern je nach Kunde oder Anwendungen, die ähnliche Daten aus unterschiedlichen Quellen gemeinsam verarbeiten müssen wie etwa Produktkataloge verschiedener Hersteller.
Für Dokumentendatenbanken weniger geeignete Einsatzgebiete sind vor allem Anwendungen mit feingranularen Domänenmodellen bzw. mit ausgeprägten Anforderungen an die analytische Auswertung der Daten.
Je weniger komplex die Aggregates des Domänenmodells sind bzw. je mehr feingranulare Aggregates das Domänenmodell enthält, desto geringer ist der Vorteil der Dokumentendatenbanken. Denn dann steigt die Anzahl der Datenbankabfragen, und die fehlende Unterstützung für Joins erschwert es, komplexe Abfragen über mehrere Dokumente hinweg zu formulieren. Vor allem bei Anwendungen mit Bedarf für ad-hoc erstellte Berichte ist die Lernkurve eher steil, solche Anforderungen sinnvoll und performant in einer Dokumentendatenbank umzusetzen.
Brauche ich nun eine Dokumentendatenbank? (Oder ist das nur eine Spielerei?)
Jeder, der schon einmal relationale Tabellen mit großen Mengen generischer Key-/Value-Werte gefüllt hat, kennt die Grenzen dieses Ansatzes. Hier hilft eine Dokumentendatenbank ungemein, auch wenn keine Web 2.0-Anwendung gebaut wird. Weiterhin profitieren alle Anwendungen, die ihre Daten auf viele relationale Tabellen verteilen müssten, wobei nur wenige dieser Tabellen Ziele eigenständiger Suchabfragen wären. Schließlich bieten Dokumentendatenbanken Lösungen, die Daten einer Anwendung massiv zu verteilen, wie es sie im relationalen Umfeld kaum gibt.
In allen anderen Fällen kann man erst einmal bei einer relationalen Datenbank bleiben. Denn hier gibt es die größte Auswahl an Produkten, die beste Tool-Unterstützung und die meisten Entwickler mit fundiertem Wissen. Gerade in kleineren Projekten kann man sich aber trotzdem mal auf das Abenteuer eines neuen Persistenz-Paradigmas einlassen. Denn dann besitzt man das Wissen, wenn man es benötigt. Und Spaß macht der Umgang mit Dokumentendatenbanken schließlich auch…
Und hier noch ein paar Tipps zum Weiterlesen: