

Microservices sind derzeit ein beliebter Ansatz für den Entwurf von Server-Anwendungen. Wer sich in einer Java-/Spring-Umgebung bewegt, sollte sich dazu mit den Netflix-Bibliotheken Ribbon, Eureka und Hystrix beschäftigen.
Bis vor kurzem war der Monolith das vorherrschende Muster beim Aufsetzen einer neuen serverseitigen Anwendung. Warum auch nicht? Solange sich die Funktionalität von einem überschaubaren Team umsetzen lässt und die Anforderungen an die Skalierbarkeit gering sind, hat der Alles-in-einem-Ansatz viele Vorteile.
Aktuell geht der Trend jedoch in Richtung Microservices. Große Anwendungen werden in fachlich in sich geschlossene Services aufgeteilt, die getrennt voneinander entwickelt und produktiv gesetzt werden. Über das Für und Wider von Microservices haben andere schon viel geschrieben (z.B Martin Fowler, Tobias Flohre oder Guido Steinacker). Angenommen, das nächste Projekt soll mit Microservices realisiert werden. Mit welchen Problemen wird man dann konfrontiert, die es in einem Monolithen nicht gibt? Und wie löst man sie?
Zunächst sollte man darüber im Klaren sein, dass es Microservices nicht umsonst gibt. Microservices sind eine Form verteilter Systeme mit all ihren Unwägbarkeiten. Wenn sich in einem Monolithen Services gegenseitig aufrufen, geschieht dies in der Regel mit Inter-Prozess-Kommunikation. Dabei kann wenig schief gehen. Bei Services, die sich in einem verteilten System aufrufen, hingegen kann sehr viel schief gehen. Darum ist bei der Entwicklung von Microservices die Erkennung und Behandlung von Fehlern noch wichtiger als in einem Monolithen.
Glücklicherweise sind diese Probleme nicht neu, und es gibt Bibliotheken, die es einem erleichtern, robuste Microservices zu entwickeln. Die Open-Source-Bibliotheken von Netflix sind dafür ein sehr gutes Beispiel. Insbesondere mit den drei Bibliotheken Ribbon, Eureka und Hystrix sowie deren Integration in Spring Boot lassen sich viele Problemfälle in den Griff bekommen.
Im Folgenden möchte ich zunächst Schritt für Schritt die verschiedenen Probleme erklären, die sich mit den genannten Bibliotheken lösen lassen. Für Eilige: Auf Github habe ich ein Projekt mit Beispiel-Code hinterlegt, das zeigt, wie man die Netflix-Bibliotheken mit Spring Boot integriert. Der Code ist reduziert auf das absolut Notwendige und soll zum Hacken einladen.
Problem 1: Load-Balancing
Eine der Vorteile von Microservices ist, dass man bei Last-Problemen die betroffenen Services einzeln skalieren kann. Fangen wir mit einem generischen Beispiel an: Ein Service Foo benötigt Funktionalität von einem Service Bar. Der Bar-Service hat viel zu tun, deswegen brauchen wir davon mehrere Instanzen.
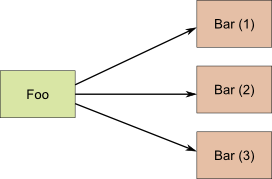
Zur Laufzeit muss der Foo-Service auf einen der Bar-Services zugreifen. Eine bewährte Lösung dafür ist es, einen Load-Balancer vor den Bar-Services einzurichten:
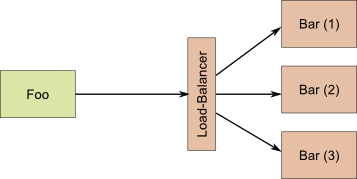
Diese Lösung ist etabliert und funktioniert gut. Neue Services werden dem Load-Balancer bekannt gemacht und sind anschließend verfügbar. Da aber jeder Service einen eigenen Load-Balancer benötigt, der auch noch redundant aufgesetzt sein muss, erhöht sich die System-Komplexität deutlich.
Eine andere Lösung besteht darin, das Load-Balancing auf die Client-Seite zu verlagern. Das heißt: Jeder Client, der einen Service aufrufen möchte, entscheidet selbst, welche der verfügbaren Instanzen er aufruft. Dazu müssen die Clients aber wissen, welche Instanzen des Services verfügbar sind.

Für diese Aufgabe gibt es Ribbon. Im einfachsten Anwendungsfall erhält Ribbon zu jedem Service eine Liste der IP-Adressen aller Instanzen des Services. Die Integration in Spring Boot geschieht mit Hilfe weniger Konfigurationseinstellungen und Annotationen. Ein RestTemplate von Spring wird so erweitert, dass Ribbon bei jedem Aufruf des Templates das Load-Balancing übernimmt, ohne dass der Java-Code dafür geändert werden muss.
Hier etwas Beispiel-Code dazu (die dazu gehörenden externen Konfigurationseinstellungen schauen Sie sich am besten auf Github an):
@SpringBootApplication
@RibbonClient(name = "bar-service", configuration=BarServiceConfiguration.class)
public class FooApplication {
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(FooApplication.class, args);
}
}
public class BarServiceConfiguration {
@Autowired
private IClientConfig ribbonClientConfig;
@Bean
public IPing ribbonPing(IClientConfig config) {
return new PingUrl();
}
@Bean
public IRule ribbonRule(IClientConfig config) {
return new AvailabilityFilteringRule();
}
}
@Service
public class FooService {
@Autowired
private RestTemplate restTemplate;
public String getMessage() {
return restTemplate.getForObject("http://bar-service/message, String.class);
}
}
Ribbon sendet von sich aus regelmäßig Pings zu allen bekannten Service-Instanzen und nimmt diejenigen Services, die darauf nicht antworten, aus seiner Liste heraus. Ausgefallene Instanzen werden somit nicht mehr aufgerufen.
Problem 2: Verzeichnis der verfügbaren Instanzen
Ein großer Nachteil in diesem Betriebsmodus ist, dass jeder Client eine statische Liste aller verfügbarer Instanzen aller verwendeten Services benötigt. Wenn eine neue Instanz eines Services in Betrieb wird, muss sie erst in diese Listen eingetragen und die Clients durchgestartet werden.
Besser wäre es, wenn eine neue Service-Instanz automatisch überall bekannt gegeben und dann aufgerufen werden könnte. Dafür gibt es Eureka.
Eureka ist eine Registrierungsstelle für Services. Jede Service-Instanz meldet sich bei einem Eureka-Server an, sodass dieser eine vollständige Übersicht hat, welche Instanzen zu jedem Service vorhanden sind. Neue Instanzen werden dynamisch hinzugefügt. Instanzen, die auf Pings nicht reagieren, werden aus den Listen entfernt. Wenn ein Client einen Service aufrufen möchte, muss er sich die aktuelle Liste vom Eureka-Server holen.
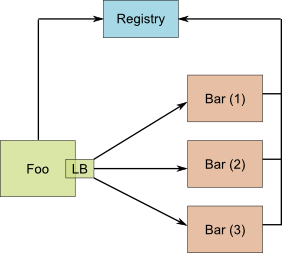
Die Entscheidung, welche Instanz aufgerufen wird, übernimmt im aufrufenden Client weiterhin Ribbon. Eureka stellt nur die Liste der Instanzen zur Verfügung. Diese Liste wird regelmäßig neu geladen, sodass sich das Wissen über neue Instanzen innerhalb kurzer Zeit (aber nicht sofort) verbreitet.
Im Java-Code (und in der Konfiguration) ändert sich nur wenig:
@SpringBootApplication
@EnableEurekaClient
@RibbonClient(name = "bar-service")
public class FooApplication {
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(FooApplication.class, args);
}
}
Problem 3: Schutz gegen Fehler-Kaskaden
Die jetzt gefundene Lösung funktioniert gut, um bei hoher Last neue Service-Instanzen dynamisch hinzuzufügen oder einzelne Instanzen herunterzufahren, beispielsweise, um eine neue Version produktiv zu setzen. Jedoch bietet diese Lösung nur Schutz gegen Fehler, die zum vollständigen Ausfall einer Service-Instanz führen.
Angenommen aber, eine Service-Instanz reagiert weiterhin auf alle Pings. Jedoch kann sie die eigene Datenbank nicht mehr erreichen – ein defekter Router lässt alle Verbindungsanfragen zur Datenbank durch, jedoch keine Antworten. In diesem Fall liefert die Service-Instanz keinen Fehler, sondern sie hängt, wenn ein Client sie aufruft. Bei hoher Last propagiert sich dieses Problem schnell über weitere Instanzen hinweg: Eine hängende Verbindung liefert kein Ergebnis, benötigt aber Ressourcen (vor allem einen freien Thread aus dem Thread-Pool). Wenn bei hoher Last ungeduldige Clients immer neue Anfragen starten, sind innerhalb kurzer Zeit alle freien Ressourcen blockiert. Die Folge ist, dass immer mehr Services hängen, auch wenn sie intern fehlerfrei laufen.
Hier helfen Sicherungen oder Circuit Breakers, die Fehler erkennen und den Zugriff auf fehlerhafte Services vollständig unterbinden. Hystrix ist dafür die passende Bibliothek.
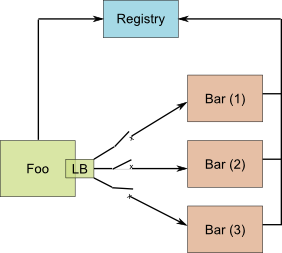
Hystrix überwacht jeden Zugriff auf einen Service und stellt fest, wie zuverlässig der aufgerufene Service antwortet. Eine Sicherung fliegt dann, wenn eine vorgegebene Regel zur Zuverlässigkeit gebrochen wird. Eine solche Regel kann lauten, dass innerhalb von 30 Sekunden nicht mehr als 5% aller Aufrufe länger als 1 Sekunde benötigen dürfen.
Wenn eine Sicherung offen ist, lässt Hystrix keine weiteren Aufrufe zu dem betroffenen Service zu. Stattdessen kann man eine explizite Fehlerbehandlung durchführen, die bestimmt, was anstelle des Service-Aufrufs getan werden soll. Hier sind alle Möglichkeiten gegeben: reines Logging, Nutzen der letzten bekannten Daten, Werfen einer eigenen Exception. Das bedeutet auch, das man sich für jeden Aufruf eines Services genau überlegen muss, was passieren soll, wenn der Service ausfällt. Dies kann man als grundsätzliche Bürde verteilter Systeme begreifen.
Oft beruhigt sich eine überlastete Instanz wieder, wenn sich die Last verringert oder nur ein kurzfristiges Problem vorlag. Aus diesem Grund lässt Hystrix auch bei offener Sicherung immer mal wieder Aufrufe durch und schließt die Sicherung, sobald diese Aufrufe zuverlässig durchgehen. Dann ist die betroffene Service-Instanz wieder vollständig erreichbar.
Auch zum Einsatz von Hystrix ist hier etwas Java-Code:
@Service
public class FooService {
@Autowired
private RestTemplate restTemplate;
@HystrixCommand(fallbackMethod = "getFallbackMessage")
public String getMessage() {
return restTemplate.getForObject("http://bar-service/message, String.class);
}
private String getFallbackMessage() {
return "Fallback only";
}
}
In der Praxis definiert man zu jedem Hystrix-Command Regeln, die die Zuverlässigkeit des jeweiligen Service beurteilen (Timeout, Toleranzschwellen für Fehler, usw.). Wenn mehrere Clients auf einen Service zugreifen, führt jeder Client für sich eine eigene Statistik und muss dementsprechend den Ausfall eines Services selbst erkennen.
Um zur Laufzeit zu überprüfen, in welchem Zustand welche Sicherung ist, gibt es von Netflix ein Dashboard als Web-Anwendung. Dieses Dashboard zeigt grafisch den Zustand der Sicherungen an und gibt dazu die wichtigsten Statistiken aus.
Hacken
Das bei Github bereit liegende Projekt bietet die Möglichkeit, mit den drei Netflix-Bibliotheken und deren Spring Boot-Integration zu experimentieren. Die Projektseite bietet eine kurze Anleitung, wie man das Projekt baut und die Tests laufen lässt.
Es gibt zwei verschiedene Szenerien zur Auswahl, die man ausprobieren kann:
- Ein Foo-Service hat eine statistische Liste von Bar-Services und greift mit Ribbon und Hystrix auf sie zu.
- Ein Eureka-Service führt eine Liste aller Services. Der Foo-Service holt sich die Liste der Bar-Services und greift damit mit Ribbon und Hystrix auf sie zu.
Fazit
Microservices bieten manche Vorteile gegenüber Monolithen, bringen jedoch auch eigene Probleme mit sich. Netflix hat diese Probleme schon alle gehabt. Aus ihrer Erfahrung heraus haben die Netflix-Entwickler Bibliotheken gebaut und als Open-Source freigegeben, die helfen, die Probleme zu bewältigen.
Die Netflix-Bibliotheken sind per Spring Boot einfach in eine Spring-Anwendung einzubinden. Man sollte sich nur klar machen, dass erfahrungsgemäß zwischen einer laufenden Testanwendung und einem stabilen Produktivbetrieb noch viele weitere kleine und große Probleme zu lösen sind.
Danke Tim für den klasse Artikel. Schön übersichtlich die Problematik bei Microservices erklärt und auch gleich Lösungen angeboten.